# Pourquoi et comment pseudonymiser dans l'administration
# Qu'est-ce que la pseudonymisation ?
# Quelle différence entre anonymisation et pseudonymisation ?
Anonymisation et pseudonymisation sont deux notions parfois difficile à distinguer, et qui concernent toutes deux la protection des données à caractère personnel.
Lexique : Donnée à caractère personnel
Toute information relative à une personne physique identifiée ou qui peut être identifiée, directement ou indirectement, par référence à un nom, un numéro d’identification (par exemple le numéro de sécurité sociale) ou à un ou plusieurs éléments qui lui sont propres.
Le guide de la CNIL sur l'anonymisation des données présente bien la différence entre anonymisation et pseudonymisation :
Lexique : Anonymisation
« L’anonymisation est un traitement qui consiste à utiliser un ensemble de techniques de manière à rendre impossible, en pratique, toute identification de la personne par quelque moyen que ce soit et ce de manière irréversible. »
Lexique : Pseudonymisation
« La pseudonymisation est un traitement de données personnelles réalisé de manière à ce qu'on ne puisse plus attribuer les données relatives à une personne physique sans avoir recours à des informations supplémentaires. En pratique la pseudonymisation consiste à remplacer les données directement identifiantes (nom, prénom, etc.) d’un jeu de données par des données indirectement identifiantes (alias, numéro dans un classement, etc.). [...] En pratique, il est toutefois bien souvent possible de retrouver l’identité de ceux-ci grâce à des données tierces. C’est pourquoi des données pseudonymisées demeurent des données personnelles. L’opération de pseudonymisation est réversible, contrairement à l’anonymisation. »
La différence entre anonymisation et pseudonymisation réside ainsi dans le caractère réversible ou non de la dissimulation des données à caractère personnel.
Un exemple de différence entre pseudonymisation et anonymisation
Supposons qu'une caisse d'allocations familiales (CAF) dispose d'une base de données contenant les noms, dates de naissance et adresses des demandeurs d'allocation logement en 2019, ainsi que les montants des allocations reçues et le nombre de personnes dans le foyer.
Si la CAF souhaite anonymiser ces données, elle pourra supprimer les informations potentiellement identifiantes comme les noms, dates de naissances et adresses, puis aggréger les montants des allocations en ne publiant par exemple que la moyenne par commune. Impossible d'identifier qui se cache derrière les allocations reçues, ce qui garantit la protection totale des données personnelles. Mais impossible aussi de comparer les bénéficiaires des années 2018 ou 2020 avec ceux de 2019, puisque l'on ne dispose pas des données à l'échelle individuelle.
Si elle souhaite pseudonymiser ces données, elle remplacera les noms et dates par un identifiant unique (au lieu de supprimer les colonnes) et remplacera les adresses complètes par les seules communes. On peut cette fois-ci comparer les identifiants entre bases pour retrouver les allocataires communs, sans pour autant être en mesure de connaître directement leur identité. Cependant, pour les communes avec un faible nombre d'habitants, les informations sur la composition du foyer pourraient être suffisantes pour réidentifier certains bénéficiaires et ainsi connaître le montant qu'ils perçoivent.
Ainsi, si l'anonymisation seule garantit une totale protection des données à caractère personnel, elle implique parfois une importante perte d'information, nécessaire à empêcher la réidentification mais limitant les réutilisations possibles des données. La pseudonymisation est donc une alternative attractive, à condition de garantir une protection suffisante.
# Pourquoi pseudonymiser des documents administratifs ?
La loi n°2016-1321 pour une République numérique fait de l’ouverture des données publiques la règle par défaut. Etalab propose par ailleurs un guide détaillé sur l'ouverture de ces données.
Lorsque les administrations diffusent dans ce cadre des documents contenant des données personnelles, l'occultation préalable des éléments à caractère personnel est généralement une obligation qui s’impose à elles en application de l'article L. 312-1-2 du Code des relations entre le public et l’administration, sauf dans certains cas particuliers.
# Quelles données personnelles dois-je retirer de mes données ?
Cela dépend du contexte réglementaire, le même cadre ne s'appliquant pas à tous les documents. Néanmoins, il conviendra la plupart du temps de pseudonymiser toute information se rapportant à une personne physique identifiée ou identifiable. Une « personne physique identifiable » est une personne physique qui peut être identifiée, directement ou indirectement, notamment par référence à un identifiant tel qu'un nom, un numéro d'identification, des données de localisation, un identifiant en ligne, ou à un ou plusieurs éléments spécifiques propres à son identité physique, physiologique, génétique, psychique, économique, culturelle ou sociale.
Pour plus de détails sur les différents cadres légaux, vous pouvez consulter le guide juridique de la publication des données publiques élaboré par la CNIL et la CADA.
Pour satisfaire à l'obligation d'occultation, la CNIL préconise d'anonymiser les documents administratifs avant de les diffuser, garantissant ainsi une parfaite impossibilité de réidentification. Néanmoins, pour les documents qui contiennent des données non structurées, en particulier du texte libre, le curseur de la « quantité d'information » à retirer d'un jeu de données pour éviter tout risque de réidentification est difficile à évaluer. De fait, une complète anonymisation est difficile à atteindre et à évaluer et peut aboutir à une trop grande perte d'informations.
Un bon exemple de document administratif pseudonymisé sont les décisions de justice, diffusées notamment sur le site Légifrance. Y sont retirés notamment les noms, prénoms, adresses, dates civiles (naissance, décès, mariage) des personnes physiques. D'autres catégories d'informations, comme les noms d'entreprises, la description de faits (dates et montants d'une transaction par exemple) pourraient permettre, en les recoupant avec d'autres informations, de réidentifier une personne physique. Cependant, retirer trop de catégories d'informations reviendrait à perdre beaucoup d'informations et appauvrirait le contenu d'une décision.
 Un extrait de décision de justice pseudonymisée
Un extrait de décision de justice pseudonymisée
Il y a donc un arbitrage à faire entre la minimisation du risque de réidentification et la préservation de l'utilité des données. Trouver le bon curseur n'est pas simple et doit passer par une double analyse des risques de réidentification, à la fois juridique (pour évaluer par exemple quelles données ne doivent pas pouvoir être réidentifiées) et technique (pour estimer la possibilité technique de réidentifier ces données). Juger de l'utilité de conserver ou non certaines catégories de données dépendra aussi des usages envisagés de ces données.
Quelle quantité de données retirer ? Un exemple fictif
Prenons l'exemple d'un extrait de décision de justice fictive : « Monsieur Dupont est accusé d'avoir cambriolé l'établissement "Café de la Paix" à Gentioux-Pigerolles, en Creuse, situé en face de son domicile, et d'avoir dérobé la recette de la semaine évaluée à 1 000€ ».
- Cas 1 : on conserve le plus d'information possible, en supprimant néanmoins les noms des personnes physiques et morales. La pseudonymisation sera par exemple : « Monsieur X. est accusé d'avoir cambriolé l'établissement "Café E." à Gentioux-Pigerolles, en Creuse, situé en face de son domicile, et d'avoir dérobé la recette de la semaine évaluée à 1 000€ ». Le problème, c'est que s'il n'y a qu'un seul café dans ce petit village, il est très aisé de comprendre de quel établissement on parle, de sa localisation et donc celle du domicile de l'accusé, et ainsi de réidentifier ce dernier si l'on est familier du village. La pseudonymisation est donc inutile et ne protège pas suffisamment les données à caractère personnel.
- Cas 2 : on conserve le moins d'information possible. On pourra alors obtenir la pseudonymisation suivante : « Monsieur X. est accusé d'avoir cambriolé l'établissement "E." à Y., en Z., situé en face de son domicile, et d'avoir dérobé la recette de la semaine évaluée à N€ ». Le problème c'est qu'il n'y a là plus beaucoup d'information utile. Par exemple, comment réaliser une cartographie du crime sans localisation ? Comment estimer les préjudices moyens des cambriolages pour un assureur ?
Un rapport du groupe de travail du G29 sur la protection des personnes à l'égard du traitement des données à caractère personnel présente une analyse détaillée des risques de réidentification après pseudonymisation, d'un point de vue juridique et technique, et des bonnes pratiques en fonction des types de données.
# Quelles sont les différentes méthodes de pseudonymisation ?
# Dans le cas où les données à caractère personnel sont tabulaires
Lorsque les données à caractère personnel sont contenues dans un jeu de données tabulaire (c'est-à-dire, pour faire simple, sous forme d'un tableau dont les lignes sont des entrées et les colonnes des catégories d'information), il est aisé de procéder directement à des traitements visant à pseudonymiser ou anonymiser, en supprimant les colonnes concernées ou en chiffrant leur contenu. Ce cas de figure n'est pas l'objet de ce guide. Pour plus d'informations à ce sujet, on se référera aux ressources de la CNIL sur l'anonymisation.
# Dans le cas où les données à caractère personnel apparaissent dans du texte libre
Lorsque les données à caractère personnel sont contenues dans du texte libre, le ciblage précis des éléments identifiants dans le texte est une tâche souvent complexe. Encore largement réalisée par des humains, cette tâche est coûteuse en temps et peut requérir une expertise spécifique dans la matière traitée (dans les textes juridiques par exemple). L'intelligence artificielle et les techniques de traitement du langage naturel peuvent permettre d'automatiser cette tâche souvent longue et fastidieuse.
# Une méthode d'automatisation simple : les moteurs de règles
Il existe des méthodes assez intuitives permettant d'automatiser la tâche de pseudonymisation, comme les moteurs de règles. Les moteurs de règles sont un ensemble de règles prédéfinies « à l'avance ». Par exemple, une règle de pseudonymisation pourrait être : « si le mot qui suit "Monsieur" ou "Madame" commence par une majuscule, alors ce mot est un prénom ». La complexité du langage naturel et la diversité des formulations qui se trouvent dans du texte libre fait que ce type de moteur de règles a de forte chance de faire beaucoup d'erreurs dans des textes administratifs dont la forme varie souvent. Il est cependant bien adapté à des textes simples, ou lorsque la méthode a besoin d'être parfaitement explicable et simplement modifiable.
# Une méthode plus complexe : l'intelligence artificielle (IA)
L'utilisation de l'IA pour automatiser la pseudonymisation de documents peut être plus ou moins pertinente. Les solutions d'IA pour pseudonymiser des données textuelles sont en grande majorité des modèles supervisés. Ces modèles d'IA dits d'apprentissage supervisé se sont beaucoup développés ces dernières années, en particulier les modèles de réseaux de neurones profonds (ou deep learning) qui sont aujourd'hui les plus performants.
Ces modèles supervisés sont des algorithmes qui prennent en entrée des données avec des labels (ou étiquettes en français), dont ils vont chercher à « apprendre » la logique d'attribution. L'objectif est ainsi que lorsqu'on leur présente une nouvelle donnée « non labelisée », l'algorithme soit capable de retrouver seul le bon label.
Dans le cas de la pseudonymisation, les données d'entrées sont chacun des mots du document à pseudonymiser et le label qu'on leur attribue est la catégorie sémantique à laquelle il se rattache : nom, prénom, adresse, etc. Ces catégories varient selon la nature du document et le degré de pseudonymisation souhaité. En traitement du langage naturel, ce type de tâche s'appelle la reconnaissance d'entités nommées (Named Entity Recognition (NER) en anglais).
Mais pour que ces modèles puissent arriver à de bonnes performances, ils nécessitent de remplir un certain nombre de prérequis. Assez exigeants, ils sont pourtant indispensables au succès de l'utilisation de l'IA appliquée à la pseudonymisation. Nous vous proposons de les passer en revue dans la section suivante.
# Quels sont les prérequis pour utiliser l'intelligence artificielle pour pseudonymiser ?
# Disposer de données brutes de qualité
La qualité des données brutes (c'est-à-dire avant tout traitement) que l'on souhaite utiliser est un premier critère essentiel qui sera déterminant pour la performance de l'algorithme. Cette qualité fait souvent référence à la facilité d'utilisation du format utilisé. En effet, les données textuelles brutes peuvent se présenter sous différents formats, plus ou moins lisibles. Idéalement, les documents textuels sont stockés au format txt ou json. Des formats moins standards (doc, pdf, png, etc..) nécessiteront des conversions afin de pouvoir être traités. Lorsque les documents sont au format image (car résultant par exemple d'une numérisation de documents papiers), la mise en place d'une brique de reconnaissance optique de caractères sera nécessaire afin de les convertir au format texte, et complexifie donc le traitement en amont du projet. La qualité des données brutes est évaluée par les data scientists en amont du projet.
# Disposer d'un grand volume des données
Essentiel également, le volume de documents annotés nécessaires dépendra de la complexité de la tâche de pseudonymisation, qui sera fonction notamment du nombre de catégories d'entités nommées retenues et de la complexité du langage utilisé dans les documents. Il est en général nécessaire de disposer de l'ordre de plusieurs milliers de documents afin d'obtenir des résultats optimaux.
# Avoir la possibilité d'annoter ses données
Puisque la tâche de notre IA consiste à reconnaître la catégorie sémantique de chaque mot, il est nécessaire en amont de tout projet de disposer « d'exemples » que l'on souhaite montrer à l'algorithme pour qu'il s'entraîne. Il sera donc nécessaire de constituer au préalable, à la main (humaine), une base d'exemples corrects. Cette tâche consistant à attribuer des labels à certains mots ou groupes de mots d'un document s'appelle l'annotation. Cette tâche pourra nécessiter des compétences spécifiques en fonction de la nature des documents et des catégories à annoter.
L'annotation, un processus exigeant et chronophage
Le processus d'annotation requiert de mobiliser des équipes souvent nombreuses (pour aller plus vite) mais aussi qualifiées. Par exemple, si vous cherchez à identifier les noms, prénoms et adresses dans un recours administratif, une simple maîtrise du français suffira. En revanche, si vous cherchez à identifier les moyens et les conclusions juridiques mentionnées, il vous faudra disposer d'une équipe de juristes expérimentés ! Pour des documents complexes, il pourra ainsi être nécessaire de mobiliser longuement des experts métiers pour obtenir une quantité d'annotation suffisante et de qualité (avec le moins de mauvais labels). On parle même de campagnes d'annotation !
Afin de constituer un ensemble de documents annotés, il est nécessaire d'utiliser un logiciel d'annotation qui permet d'enregistrer les annotations réalisées par les annotateurs. Il existe de nombreux logiciels d'annotation, dont beaucoup sont open source comme Doccano.
# Avoir accès à des infrastructures de calcul adéquates
L'entraînement de modèles de traitement du langage récents, basés sur des réseaux de neurones profonds (deep learning), nécessite des ressources dédiées et exigeantes. D'une part, la volumétrie de données nécessaires pour l'entraînement peut mener à la constitution de corpus de plusieurs giga voire téraoctets et peut nécessiter des infrastructures de stockages dédiées, comme des serveurs de stockage. D'autre part, l'entraînement des modèles est pour sa part très gourmand en capacités de calcul, et s'appuie notamment des processeurs graphiques (GPU en anglais) qui permettent d'accélérer considérablement le temps de calcul. Même en disposant de GPU de dernières générations, il faut compter plusieurs jours voire plusieurs semaines pour un apprentissage complet du modèle.
En résumé, de nombreuses conditions doivent être remplies avant de se lancer dans un projet d'utilisation de l'IA pour la pseudonymisation. Voici résumé le questionnement logique à suivre :
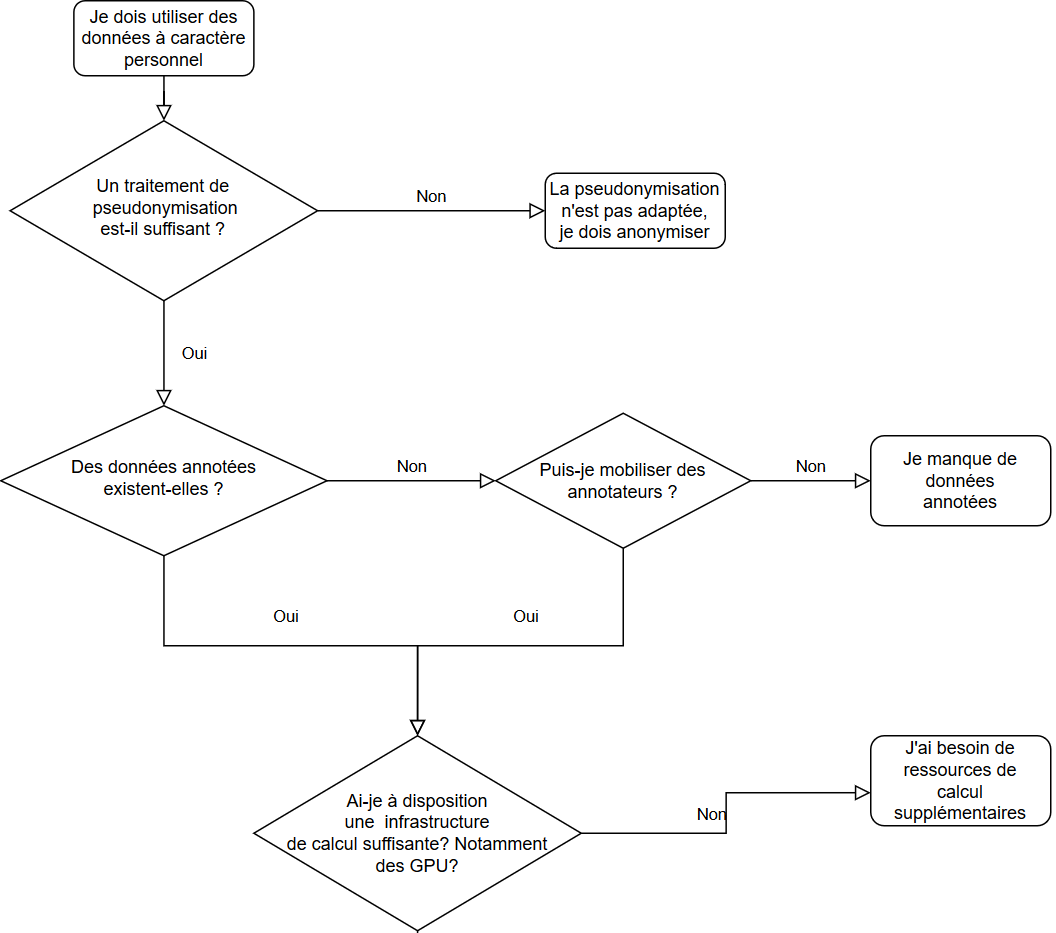
# Ressources externes
- Guide de l'anonymisation pour les données ouvertes de la CNIL
- Guide pratique (juridique) de la publication en ligne et de la réutilisation des données publiques élaboré par la CNIL, la CADA et Etalab
- Guide RGPD du développeur de la CNIL
- Avis sur les techniques d’anonymisation du Groupe de travail du G29 sur la protection des personnes à l'égard du traitement des données à caractère personnel
- Guide « Pseudonymisation techniques and best practices » de l’Agence Européenne de Cybersécurité (ENISA)